Principalmente, el estudio ayuda a corroborar la premisa de que el análisis matemático puede ser una herramienta valiosa para el análisis de interacciones entre usuarios de redes sociales. Aunque el alcance del estudio no permite generalizar, en el ámbito de los casos estudiados se observa: (i) entre más diversa la discusión, menos tóxica la interacción; (ii) comentarios a noticias son más tóxicos que Tweets; (iii) hay más usuarios no tóxicos que tóxicos, pero la toxicidad no se concentra en pocos usuarios; (iv) el uso de hashtags, ser un usuario visible y tener foto de perfil se asocia con mensajes menos tóxicos; (v) se presentan más mensajes tóxicos de hombres a mujeres que al revés; (vi) la audiencia es pasiva a la hora de tratar de calmar discusiones agresivas.
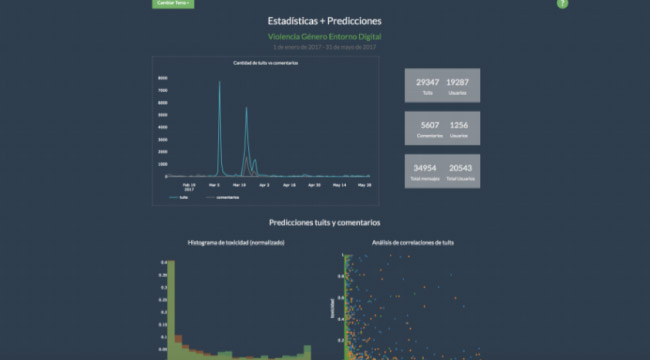
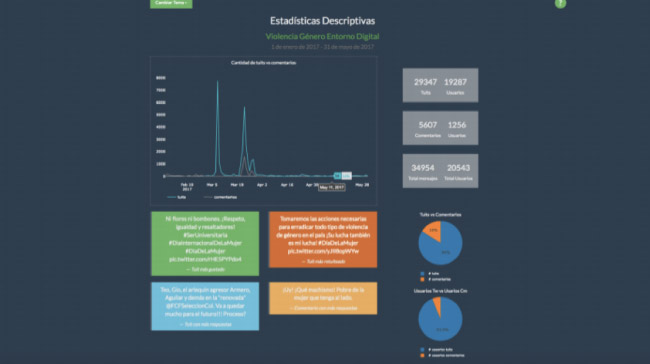
Para los dos casos de estudio seleccionados (“Grupo Político” y “Violencia de Género en Ámbitos Digitales”) se recolectaron 69,717 tweets, y 10,400 comentarios históricos de los portales de los principales medios digitales del país. Adicionalmente, se extrajo la información (id, número de seguidores, seguidos, favoritos, entre otros) de 35,919 usuarios de Twitter que participaron en las conversaciones de los temas de interés.
Para este ejercicio, se marcaron 1500 tweets y 500 comentarios para cada caso. Las marcaciones se realizaron de manera manual entre tres categorías: toxicidad, provocación y calma. Posteriormente, se entrenaron distintos modelos de clasificación como regresión logística, Naive Bayes, Boosted Trees y Support Vector Machines con kernel lineal y se predijo el nivel de toxicidad, provocación y calma para cada mensaje en la base de datos. Debido a la ambigüedad en la definición y marcación del nivel de provocación, los modelos alcanzan un máximo de 0.76 de área bajo la curva ROC para el mejor modelo. La característica de “provocación” fue la más difícil de clasificar alcanzando un área máxima de 0.66.
Para enriquecer el análisis, se identificaron usuarios anónimos, usuarios visibles en la conversación y cuentas automatizadas (“bots”). Se tomaron distintas características de los perfiles de los usuarios de Twitter para segmentarlos en distintos grupos utilizando un algoritmo de k-medias. Por ejemplo, para identificar a los usuarios anónimos se utilizaron las variables que indican si la cuenta es verificada, si el nombre utilizado tienen un género definido, si tiene habilitado el sistema de georreferenciación y si ha cambiado la imagen original de su perfil. Una vez se identifican los grupos, se les asigna manualmente a cada uno una calificación de anonimidad según las variables de cada grupo.